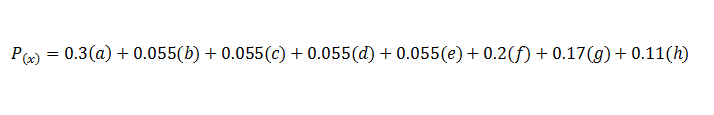El teorema de Bayes, una herramienta fundamental en el campo de la inferencia estadística y el aprendizaje automático, ofrece un marco poderoso para actualizar nuestras creencias a medida que adquirimos nueva información. En este artículo, exploraremos cinco razones científicas y técnicas para preferir el enfoque bayesiano sobre el uso simple de la probabilidad previa.
Incorporación de nueva evidencia: El teorema de Bayes nos permite integrar nueva evidencia en nuestras estimaciones de manera sistemática. Según Gelman et al. (2013), esta capacidad de actualizar nuestras creencias con nueva información es esencial para la toma de decisiones informadas en diversos campos.
Manejo de la incertidumbre: Bayes proporciona un marco formal para manejar la incertidumbre en nuestros modelos y estimaciones. Wasserman (2004) destaca que esta habilidad para cuantificar y gestionar la incertidumbre es crucial en la modelización estadística, donde rara vez tenemos información completa.
Flexibilidad en la modelización: El enfoque bayesiano ofrece flexibilidad en la elección de modelos y la incorporación de información previa. Kass y Raftery (1995) subrayan que esta flexibilidad es especialmente valiosa cuando contamos con conocimiento previo sobre el problema que estamos abordando.
Inferencia robusta: El enfoque bayesiano proporciona una inferencia más robusta, especialmente en casos de datos escasos o muestras pequeñas. Carlin y Louis (2010) señalan que este enfoque permite una inferencia más estable y confiable al utilizar toda la información disponible de manera óptima.
Actualización continua: Una característica distintiva del enfoque bayesiano es su capacidad para actualizar continuamente nuestras creencias a medida que se acumula más evidencia. Esto facilita una toma de decisiones dinámica y adaptable en entornos cambiantes, como sugiere Kruschke (2014).
Para ilustrar la aplicación del teorema de Bayes, consideremos una analogía con el ajedrez. Al igual que en el juego, nuestra estrategia inicial se basa en nuestro conocimiento previo y experiencia. Sin embargo, a medida que avanza la partida y nuestro oponente realiza movimientos inesperados, necesitamos adaptar nuestra estrategia en tiempo real. El teorema de Bayes actúa como nuestro proceso de adaptación, permitiéndonos actualizar nuestras estrategias con cada movimiento de nuestro oponente y ajustar nuestras acciones en consecuencia. Así, Bayes nos ayuda a tomar decisiones más informadas y efectivas en un entorno cambiante y competitivo, de manera similar a su papel en el análisis estadístico.
Referencias bibliográficas:
Carlin, B. P., & Louis, T. A. (2010). Bayesian methods for data analysis (3rd ed.). CRC Press.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian data analysis (3rd ed.). CRC Press.
Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773-795.
Kruschke, J. K. (2014). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd ed.). Academic Press.
Wasserman, L. (2004). All of statistics: A concise course in statistical inference. Springer.
En el vasto tejido del universo, donde los números danzan al compás de las ecuaciones, existe un número que destaca entre todos por su misterio y su belleza: el número Pi. Desde tiempos inmemoriales, Pi ha fascinado a matemáticos, filósofos y poetas por igual, pues encarna la esencia misma de lo irracional y lo infinito.
Comienzo este relato con la jornada laboral, donde la precisión y la exactitud son herramientas indispensables para alcanzar el éxito. En este mundo de números y medidas, Pi emerge como un aliado silencioso pero poderoso. Como señaló el renombrado matemático Carl Friedrich Gauss, «Pi es la constante misteriosa que se oculta detrás de cada cálculo, confiriendo orden y estructura a nuestro universo numérico». En cada ingenio, en cada fórmula, Pi se revela como el hilo conductor que une las complejas redes de la ciencia y la tecnología. Desde la construcción de rascacielos hasta el diseño de circuitos electrónicos, Pi está presente en cada paso del camino, recordándonos la importancia de la precisión y la disciplina en nuestro trabajo diario.
Pero Pi no se limita a las frías paredes del laboratorio o la oficina; su influencia se extiende mucho más allá, alcanzando incluso los reinos más profundos del corazón humano. En el juego del amor, donde las reglas son tan elusivas como el propio Pi, encontramos una conexión sorprendente entre la pasión y la irracionalidad. Como escribió el poeta Rumi, «El amor es un número irracional que no puede ser definido por las leyes de la lógica o la razón». En efecto, el amor desafía toda explicación racional, manifestándose en formas impredecibles y sorprendentes. Al igual que Pi, el amor es infinito en su complejidad, imposible de encerrar en una fórmula o una ecuación. Es un misterio que nos impulsa a explorar los límites de nuestra propia humanidad, recordándonos que, a veces, las cosas más hermosas son también las más inexplicables. Acá dejo un poema sobre Pi, que describe un poquito estas aristas:
Pi…
En el cielo estrellado, Pi se alza triunfante,
Infinito en su grandeza, misterioso y constante.
Tres, punto, uno, cuatro, su secuencia sin final,
En cada círculo y espiral, su huella celestial.
En el mundo de los números, Pi es el rey,
Irracional y eterno, sin fin ni por qué.
En cada ecuación, en cada fórmula precisa,
Pi se revela, símbolo de belleza intrínseca.
Desde Pitágoras hasta Euler, su legado perdura,
En cada mente curiosa, su magia perdura.
En honor a Pi, este poema se alza,
Celebrando su grandeza, ¡oh número sin traza!
En el universo matemático, Pi ocupa un lugar único como el prototipo de los números irracionales. Su secuencia infinita de dígitos, aparentemente caótica y sin patrón discernible, encierra un poderoso mensaje sobre la naturaleza misma del cosmos. Como el matemático y filósofo Pitágoras enseñó, «El universo es un vasto océano de números en constante movimiento, y Pi es el flujo que lo atraviesa todo». En cada círculo, en cada espiral, encontramos la impronta de Pi, recordándonos la inseparable conexión entre la belleza y la irracionalidad. En un mundo regido por leyes matemáticas implacables, Pi nos recuerda que la verdadera grandeza reside en la capacidad de abrazar lo desconocido, de explorar los rincones más oscuros de la mente humana en busca de la verdad última.
La vida y el número Pi están intrínsecamente entrelazados en un baile eterno de precisión y misterio. Desde las alturas del conocimiento científico hasta las profundidades del corazón humano, Pi nos acompaña en nuestro viaje, recordándonos la belleza de lo irracional y la importancia de abrazar lo desconocido. En las palabras del matemático Leonhard Euler, «Pi es más que un número; es un símbolo de la infinitud misma, una puerta abierta hacia lo desconocido». En nuestro trabajo, en nuestro amor y en nuestra exploración del universo, Pi nos guía, recordándonos que, en última instancia, somos parte de un cosmos vasto e infinito, donde la belleza y la irracionalidad van de la mano.
Las encuestas electorales han sido objeto de críticas y escepticismo en Guatemala debido a sus fallas en la predicción precisa de los resultados. Existen varias razones que explican estas inconsistencias y permiten entender por qué las encuestas a menudo no reflejan fielmente la realidad política del país. Entre las principales aristas destacan: la influencia de los partidos políticos en la elaboración y difusión de encuestas sesgadas, los sesgos en los medios de publicación y los errores estadísticos.
En primer lugar, la mayoría de los partidos políticos guatemaltecos tienen la práctica común de encargar sus propias encuestas, lo cual puede generar sesgos significativos. Al financiar y difundir sus propias encuestas, estos partidos pueden influir en los resultados y manipular la percepción de la opinión pública. Esto puede conducir a una falta de transparencia y confianza en las encuestas, ya que los datos publicados pueden estar sesgados a favor de los intereses de los partidos políticos involucrados.
Otra razón importante es la presencia de sesgos en los medios de publicación. Los medios de comunicación desempeñan un papel fundamental en la difusión de los resultados de las encuestas, pero su influencia y posicionamiento pueden afectar la imparcialidad de la información. Los medios pueden tener afinidades políticas o intereses comerciales que influyen en la forma en que presentan los resultados de las encuestas, lo que puede sesgar la percepción de la opinión pública y llevar a una comprensión distorsionada de la realidad política.
Además, no se pueden descartar los errores estadísticos inherentes a las encuestas. Estos errores pueden deberse a diversos factores, como el tamaño de la muestra, la forma en que se selecciona a los encuestados o el margen de error permitido. Los errores estadísticos son comunes en cualquier estudio de opinión pública y pueden contribuir a la falta de precisión en los resultados proyectados.
Los errores en las encuestas electorales pueden ser vistos a través del prisma de la falsación propuesta por Karl Popper. Según Popper, ninguna teoría o predicción puede ser considerada verdadera o absoluta, sino que solo puede ser corroborada o falsada mediante la evidencia empírica. En el caso de las encuestas, los errores y sesgos revelan las limitaciones inherentes a la predicción precisa de resultados electorales. Como dijo Leonhard Euler, uno de los más grandes matemáticos de la historia, «No es suficiente tener una mente buena, lo principal es aplicarla bien». Esto nos recuerda la importancia de estimar correctamente los resultados, reconociendo las limitaciones y buscando mejorar constantemente los métodos utilizados en la recolección y análisis de datos electorales.
Las razones detrás de las fallas en las encuestas en Guatemala se pueden atribuir a diferentes factores. La influencia de los partidos políticos en la elaboración de encuestas sesgadas, los sesgos en los medios de publicación y los errores estadísticos son las principales aristas que explican estas inconsistencias. Para mejorar la calidad de las encuestas y fortalecer la confianza en los resultados, es necesario promover la independencia y transparencia en la elaboración de encuestas, así como una mayor vigilancia y evaluación crítica por parte de la ciudadanía y los expertos en estadística. Solo a través de un enfoque riguroso y transparente podremos avanzar hacia una mejor comprensión de la realidad política de Guatemala.
Definición: El concepto presentado por Clarke O. Cochran y Eloise Malone1 plantea que la política pública consiste en la toma de decisiones políticas para implementar programas con el fin de alcanzar metas sociales. Esta definición resalta la naturaleza política de las políticas públicas y su propósito fundamental de abordar necesidades y desafíos de la sociedad en su conjunto.
Opinión: La política pública implica la intervención del gobierno en la sociedad mediante la adopción de medidas y programas específicos. Estas decisiones políticas son el resultado de un proceso complejo que involucra la identificación de problemas, la formulación de metas, el análisis de opciones y la toma de decisiones sobre las acciones a emprender. A través de estos programas, se busca promover el bienestar general, mejorar la calidad de vida de los ciudadanos y abordar cuestiones sociales prioritarias.
En mi opinión, la definición presentada refleja acertadamente la naturaleza política y estratégica de la política pública. La toma de decisiones políticas y la implementación de programas son herramientas fundamentales para abordar los desafíos y promover el desarrollo social. Sin embargo, es importante destacar que la política pública debe ser guiada por principios de equidad, eficiencia y participación ciudadana, para garantizar que las metas sociales se logren de manera justa y sostenible.
_________
1 “Consist of political decisions for implementing programs to achieve societal goals”. (Clarke O. Cochran y Eloise Malone. Citado en Birkland, Thomas. An introduction to the policy process: theories, concepts and models… Pág. 18, cap. 1. Google books).
Después de un análisis y discusión de los factores críticos en la gestión por procesos, se seleccionaron estadísticamente los 6 factores más relevantes. Estos factores son el compromiso y liderazgo de la alta dirección, el alineamiento de los procesos con los objetivos y estrategias institucionales, la participación activa y compromiso de los empleados, la disponibilidad de recursos, la comunicación efectiva y el monitoreo y medición de los procesos. Estos factores representan elementos fundamentales para el éxito de la gestión por procesos y deben recibir especial atención y enfoque estratégico en las organizaciones. Su adecuada gestión y desarrollo contribuirá a mejorar la eficiencia y efectividad de los procesos organizativos.
Palabras clave: gestión por procesos, administración pública, liderazgo, participación de los trabajadores, empoderamiento, recursos humanos, recursos financieros, recursos tecnológicos, mejora continua.
Abstract:
This study aimed to identify critical factors in process management. After analysis and discussion, six statistically significant factors were selected: leadership commitment, alignment with institutional objectives, active employee participation, resource availability, effective communication, and process monitoring. These factors are essential for successful process management and require strategic management. Proper attention and development of these factors will enhance organizational process efficiency and effectiveness.
Keywords: process management, public administration, critical factors, leadership, worker participation, empowerment, human resources, financial resources, technological resources, continuous improvement.
I-. Introducción:
La gestión eficiente de los procesos es crucial para el éxito de las organizaciones en la actualidad. Identificar los factores críticos que influyen en esta gestión se vuelve fundamental para mejorar la eficiencia y la efectividad de los procesos. En este estudio, se utilizó un enfoque metodológico basado en el método Saaty AHP y pruebas estadísticas no paramétricas para identificar los factores críticos en la gestión por procesos.
En primer lugar, se recopilaron experticias y conocimientos de diversos profesionales en el área de gestión por procesos. A través de sesiones de discusión y análisis, se identificaron catorce factores que se consideraron relevantes en el contexto de la gestión por procesos. Estos factores incluyeron el compromiso y liderazgo de la alta dirección, el alineamiento de los procesos con los objetivos institucionales, la participación activa de los empleados, la disponibilidad de recursos, la comunicación efectiva, el monitoreo y medición de los procesos, la definición clara de los procesos clave, la asignación adecuada de recursos, la integración con otros sistemas de gestión, el desarrollo de procedimientos y manuales, la mejora continua, la gestión de riesgos, la capacitación y desarrollo de habilidades, y la revisión por la dirección.
A continuación, se aplicó el método Saaty AHP para jerarquizar estos factores y determinar sus pesos relativos. Mediante un proceso de comparación pareada, los expertos asignaron valores numéricos a cada factor, reflejando su importancia relativa en la gestión por procesos. Los resultados revelaron que seis factores destacaron significativamente: el compromiso y liderazgo de la alta dirección, el alineamiento de los procesos con los objetivos institucionales, la participación activa de los empleados, la disponibilidad de recursos, la comunicación efectiva y el monitoreo y medición de los procesos.
Para confirmar la significancia estadística de estos resultados, se aplicó la prueba no paramétrica K-means. La prueba mostró que existían diferencias estadísticamente significativas entre los pesos de los factores, respaldando así la importancia de los seis factores seleccionados.
2.1-. Gestión por procesos
La gestión por procesos es una metodología que se utiliza en la administración de empresas para mejorar la eficiencia y efectividad de una organización. Se centra en la identificación, análisis, diseño, implementación y mejora continua de los procesos de una empresa, con el objetivo de lograr mejores resultados y aumentar la satisfacción del cliente.
En la gestión por procesos, se considera a la organización como un conjunto de procesos interrelacionados, que se enfocan en la generación de valor para el cliente. Los procesos se definen como una secuencia de actividades que transforman entradas en salidas, y que agregan valor a través de la creación de productos o servicios.
La metodología de gestión por procesos implica la identificación y documentación de los procesos de una empresa, la evaluación de su eficacia y eficiencia, y la mejora continua de los mismos. También se enfoca en la asignación de responsabilidades y la definición de indicadores de desempeño para cada proceso, lo que permite monitorear su desempeño y medir su éxito.
La gestión por procesos ayuda a las instituciones a optimizar su estructura organizativa y a alinear sus objetivos con los procesos necesarios para alcanzarlos, lo que permite mejorar la toma de decisiones y aumentar la eficiencia operativa. En resumen, la gestión por procesos es una metodología que se enfoca en la mejora continua de los procesos de una institución para alcanzar mejores resultados y aumentar la satisfacción de la población a quien atiende.
2.2-. Administración pública
Administración pública: se refiere a la gestión y dirección de los asuntos públicos por parte de las instituciones y organismos del Estado encargados de proveer servicios y bienes públicos para satisfacer las necesidades y demandas de la sociedad. Según Aguilar (2013), «la administración pública es un conjunto de órganos, instituciones, empresas y entidades encargados de prestar servicios y llevar a cabo acciones para satisfacer las necesidades y demandas de la sociedad, a través de la gestión de los recursos públicos» (p. 25).
2.3-. Beneficios y retos de la implementación de la gestión por procesos en la administración pública
La implementación de la gestión por procesos en la administración pública presenta diversos beneficios, tales como la mejora de la eficiencia y eficacia de los procesos, la reducción de costos y tiempos de ejecución, la identificación y solución de problemas en los procesos, y la orientación hacia resultados y objetivos. Según López et al. (2018), la gestión por procesos también contribuye a la mejora de la calidad del servicio público, la satisfacción de los usuarios y la transparencia en la gestión pública.
Sin embargo, la implementación de la gestión por procesos en la administración pública también presenta retos, como la resistencia al cambio por parte de los empleados, la falta de recursos y capacidades, la dificultad de medir los resultados y la necesidad de una cultura organizacional orientada a procesos. Según Córdoba (2019), es importante abordar estos retos para lograr una implementación efectiva de la gestión por procesos en la administración pública y aprovechar al máximo sus beneficios.
La implementación de la gestión por procesos en la administración pública implica una transformación cultural en la manera en que se llevan a cabo los procesos y la forma en que se toman decisiones. Por lo tanto, es importante que los líderes gubernamentales entiendan los beneficios y los retos que implica esta implementación para poder guiar a sus equipos de manera efectiva en este cambio.
Entre los beneficios de la gestión por procesos en la administración pública, se encuentra la mejora en la calidad del servicio público que se brinda a los ciudadanos. Al estar enfocado en la satisfacción del usuario, la gestión por procesos implica la identificación y corrección de problemas en los procesos, lo que a su vez mejora la eficiencia y eficacia en la prestación de servicios. Asimismo, al orientar la gestión hacia los resultados, se logra una mayor transparencia y rendición de cuentas en la administración pública.
Sin embargo, la implementación de la gestión por procesos en la administración pública puede presentar retos importantes. Uno de los más significativos es la resistencia al cambio por parte de los empleados. En este sentido, es importante involucrar y capacitar a los empleados en la nueva forma de trabajo para garantizar su compromiso y participación en la implementación de la gestión por procesos. Además, la implementación de la gestión por procesos requiere de recursos y capacidades, lo que puede presentar un desafío en contextos de limitaciones presupuestarias.
2.4-. Factores críticos de éxito en la implementación de la gestión por procesos en la administración pública: definición y clasificación
Por medio de un proceso recopilación de datos a 4 especialistas en gestión por procesos se determinaron 14 puntos críticos:
Compromiso y liderazgo de la alta dirección: Se refiere a la disposición y compromiso de los líderes y directivos de una organización para promover y respaldar la implementación de un sistema de gestión por procesos. Implica establecer metas claras, proporcionar recursos y apoyo, y ejercer un liderazgo efectivo para fomentar el cambio y la mejora continua.
Alineamiento de los procesos con los objetivos y estrategias institucionales: Este factor se centra en asegurar que los procesos de la organización estén alineados con los objetivos y estrategias establecidos. Implica diseñar, documentar y ejecutar los procesos de manera coherente con la visión y dirección estratégica de la organización, para garantizar que contribuyan a alcanzar los resultados deseados.
Participación activa y compromiso de los empleados: Este factor se refiere a la implicación y compromiso de los empleados en la gestión por procesos. Involucra promover una cultura de participación, fomentar la colaboración y empoderar a los empleados para que asuman responsabilidad en la mejora de los procesos, aportando ideas, compartiendo conocimientos y trabajando en equipo.
Disponibilidad de recursos: Este factor se relaciona con la asignación adecuada de recursos necesarios para la ejecución y mejora de los procesos. Incluye proporcionar los recursos financieros, tecnológicos, humanos y materiales necesarios para asegurar la eficiencia y eficacia de los procesos, así como la capacidad de respuesta ante los requerimientos operativos.
Comunicación efectiva: Se refiere a establecer canales de comunicación claros y eficientes en la organización, tanto vertical como horizontalmente. Implica transmitir información relevante sobre los procesos, compartir los objetivos y logros, y facilitar la comunicación abierta y bidireccional entre los distintos niveles y áreas de la organización.
Definición clara de los procesos clave: Este factor implica tener una comprensión clara y precisa de los procesos clave que generan mayor impacto en los resultados de la organización. Implica identificar, documentar y establecer los procesos críticos para el logro de los objetivos, definir sus responsabilidades y secuencias, y asegurar que sean entendidos por todos los involucrados.
Asignación de recursos adecuados: Este factor se refiere a asignar los recursos necesarios de manera adecuada para cada proceso. Implica identificar las necesidades de recursos, tanto humanos como materiales, y asegurar que sean asignados de manera equilibrada y oportuna para garantizar la operación eficiente de los procesos.
Monitoreo y medición de los procesos: Este factor implica establecer mecanismos de seguimiento y medición de los procesos para evaluar su desempeño. Incluye definir indicadores clave, recolectar datos relevantes, analizar los resultados y tomar acciones correctivas o de mejora con base en la información obtenida.
Integración con otros sistemas de gestión: Se refiere a la capacidad de los procesos de integrarse con otros sistemas de gestión existentes en la organización, como sistemas de calidad, ambientales o de seguridad.
Desarrollo de procedimientos y manuales: Este factor se refiere al diseño y desarrollo de procedimientos y manuales que describan de manera clara y detallada los pasos a seguir en la ejecución de los procesos. Implica establecer guías y documentos que especifiquen las actividades, responsabilidades, secuencias y requisitos necesarios para llevar a cabo los procesos de manera estandarizada y consistente.
Mejora continua: Este factor se centra en la cultura y el enfoque de la organización hacia la mejora continua de los procesos. Implica promover la identificación de oportunidades de mejora, la implementación de acciones correctivas y preventivas, el análisis de resultados y el aprendizaje organizacional, con el objetivo de optimizar la eficiencia, calidad y resultados de los procesos.
Gestión de riesgos: Este factor se relaciona con la identificación, evaluación y gestión de los riesgos asociados a los procesos. Implica analizar y comprender los posibles riesgos que puedan afectar la ejecución de los procesos, establecer medidas preventivas y de mitigación, y monitorear de forma continua para garantizar la minimización de los impactos negativos y la maximización de las oportunidades.
Capacitación y desarrollo de habilidades: Este factor se refiere a la inversión en el desarrollo de habilidades y competencias necesarias para llevar a cabo los procesos de manera efectiva. Implica proporcionar capacitación, formación y oportunidades de desarrollo profesional a los empleados, con el fin de mejorar su desempeño, conocimientos técnicos y capacidades para contribuir al éxito de los procesos.
Revisión por la dirección: Este factor implica la participación y revisión regular de la alta dirección en la gestión por procesos. Implica llevar a cabo evaluaciones y revisiones periódicas de los resultados y desempeño de los procesos, establecer acciones correctivas y estrategias de mejora, y asegurar la alineación con los objetivos estratégicos y las políticas organizacionales.
Estos factores son fundamentales en el diseño y la implementación de un sistema de gestión por procesos eficaz, y su enfoque adecuado contribuye a la optimización de los resultados y el logro de los objetivos organizacionales.
2.5-. Metodología para el análisis
La elección de descartar métodos paramétricos en este estudio se basó en razones técnicas fundamentales. Las pruebas paramétricas requieren suposiciones sobre la distribución de los datos, como la normalidad y la homogeneidad de varianzas. Sin embargo, al analizar los datos primarios extraídos en este estudio de gestión de procesos, se encontró que no cumplían con estas suposiciones. La distribución de los datos no seguía una forma normal y se observaban desviaciones significativas en las varianzas entre los grupos de datos. Como resultado, los métodos paramétricos no serían apropiados ni confiables para aplicar en este contexto. En lugar de eso, se optó por utilizar enfoques no paramétricos, que son más flexibles y no requieren de estas suposiciones estrictas sobre los datos. Esto permitió obtener resultados más precisos y robustos en la identificación de los factores críticos y en la posterior agrupación de los mismos.
El uso del modelo Saaty en este contexto es fundamental para establecer una jerarquía y asignar pesos a los 14 factores identificados. Saaty proporciona una metodología estructurada y matemática para la toma de decisiones multicriterio, permitiendo evaluar y comparar los factores de manera objetiva. A través de su proceso de comparación y asignación de valores numéricos, Saaty ayuda a determinar la importancia relativa de cada factor y facilita la toma de decisiones informadas. Al utilizar Saaty, se promueve la consistencia y el rigor en el análisis, lo que contribuye a una mejor comprensión de la importancia de cada factor y a la identificación de las áreas clave en la gestión por procesos.
El modelo de Saaty, también conocido como el Proceso Analítico Jerárquico (AHP, por sus siglas en inglés), es una metodología desarrollada por Thomas L. Saaty para determinar el peso relativo de diferentes criterios o factores de éxito en un proceso de toma de decisiones. El modelo AHP se basa en la comparación de pares de criterios y utiliza una escala de valores para establecer las preferencias entre ellos. El procedimiento del modelo AHP consta de cinco aspectos fundamentales:
Jerarquización de los criterios: En primer lugar, se identifican los criterios o factores de éxito relevantes para el problema en cuestión. Estos criterios se organizan en una estructura jerárquica, donde el criterio principal se encuentra en la parte superior y los subcriterios se ubican en niveles inferiores.
Comparación de pares de criterios: Se realiza una comparación sistemática de los pares de criterios para establecer sus relaciones de importancia relativa. Para ello, se utiliza una escala de valores que va desde 1 (igual importancia) hasta 9 (absoluta importancia). Los valores intermedios se utilizan para reflejar la importancia relativa entre los criterios.
Construcción de la matriz de comparación: A partir de las comparaciones de pares de criterios, se construye una matriz de comparación que refleja las preferencias de importancia relativa. Esta matriz es cuadrada y simétrica, donde los elementos de la diagonal principal son siempre iguales a 1.
Cálculo de los pesos relativos: Mediante un proceso de cálculo matemático, se determinan los pesos relativos de los criterios a partir de la matriz de comparación. Esto implica obtener los valores propios y los vectores propios de la matriz, y normalizar los vectores propios para obtener los pesos relativos.
Verificación de la consistencia: Se evalúa la consistencia de las comparaciones realizadas mediante la aplicación del Índice de Consistencia (CI) y la Relación de Consistencia (CR). Estos indicadores permiten verificar que las comparaciones sean razonables y coherentes. Si el CR supera un umbral predefinido, se considera que las comparaciones no son consistentes y se deben revisar.
La ecuación fundamental del método de Saaty para el Proceso Analítico Jerárquico (AHP) es la siguiente:
Ax = λx
Donde:
A es la matriz de comparación de pares, de tamaño nxn, que contiene los valores de las preferencias relativas entre los criterios.
x es el vector propio principal, de tamaño nx1, que representa los pesos relativos de los criterios.
λ es el valor propio principal, que indica la consistencia de las comparaciones realizadas.
El modelo de Saaty es una metodología estructurada y sistemática para determinar los pesos relativos de los criterios o factores de éxito en un proceso de toma de decisiones. Permite obtener una jerarquía de importancia relativa que ayuda a asignar los recursos y la atención adecuada a los diferentes criterios.
Para categorizar los datos en 4 grupos mediante clustering, se utilizó un algoritmo de clustering K-means. El K-means es un método de agrupamiento que busca dividir los datos en k grupos basados en sus características similares.
Y en segunda instancia se utilizó el algoritmo de K-means, que es una forma matemática de representar el algoritmo utilizado para encontrar los centroides y asignar los puntos a los grupos. La ecuación se compone de dos pasos principales: asignación y actualización de centroides, a continuación se presenta la asignación de los centroides:
arg min ||x – μ_k||^2
Donde:
x es el punto que se está asignando.
μ_k es el centroide del grupo k.
||…||^2 representa la distancia euclidiana al cuadrado entre el punto y el centroide.
Actualización de centroides:
Una vez que todos los puntos han sido asignados a los grupos, los centroides se actualizan recalculando su posición media. La ecuación de actualización se puede escribir de la siguiente manera:
μ_k = (1 / N_k) * Σ x_i
Donde:
μ_k es el nuevo centroide del grupo k.
N_k es el número de puntos asignados al grupo k.
Σ x_i representa la suma de todos los puntos asignados al grupo k.
A continuación se muestra:
Preparación de los datos: Se organizó los datos en una matriz o tabla donde cada fila representa una observación y cada columna representa una variable. En este caso, tendríamos 14 filas (una por cada variable) y 1 columna (representando los pesos).
Se seleccionó del número de clusters: Decidir el número de clusters (en este caso, 4) es una decisión subjetiva basada en el contexto y el objetivo del análisis. En algunos casos, se puede utilizar la técnica del codo (elbow method) o el análisis de silueta para determinar el número óptimo de clusters.
Y se aplicó el algoritmo K-means: Utilizando un software de análisis de datos o un lenguaje de programación Python, se aplicó el algoritmo K-means a los datos con el número de clusters seleccionado. El algoritmo asignó cada variable al grupo correspondiente.
2.6-. Resultados de la jerarquización
Esta metodología permitió establecer una jerarquía y asignar pesos a los factores críticos identificados en un proceso de toma de decisiones. Al utilizar el modelo Saaty, se promueve la consistencia y el rigor en el análisis, lo que contribuye a una mejor comprensión de la importancia de cada factor y a la identificación de las áreas clave en la gestión por procesos. El valor de RC (relación de consistencia) obtenido fue 6.76% muestra la consistencia y objetividad del estudio. Mediante la prueba K-means con K=4, se obtuvo una inercia de 8.68 y un punto de silueta de 0.678, indicando un buen ajuste de los datos a los centroides propuestos y la significancia de los clústeres identificados. Los resultados fueron:
2.7-. Descripción de los Principales Factores de éxito en la implementación de la Gestión por Procesos
La gestión por procesos se ha convertido en una herramienta esencial para mejorar la eficiencia, eficacia y transparencia en la administración pública. La implementación de la gestión por procesos puede ayudar a optimizar los procesos en la administración pública, lo que a su vez puede mejorar la calidad de los servicios ofrecidos a la ciudadanía. Sin embargo, la implementación exitosa de la gestión por procesos en la administración pública requiere de la consideración de 5 factores críticos demostrados estadísticamente.
Entre los principales factores críticos para el éxito en la implementación de la gestión por procesos en la administración pública, se destacan la necesidad de un liderazgo comprometido por parte de la alta dirección, la participación activa y el empoderamiento de los trabajadores, y la disponibilidad de recursos humanos, financieros y tecnológicos. La alta dirección debe liderar con el ejemplo y proporcionar el apoyo y los recursos necesarios para establecer un sistema de gestión por procesos sólido y sostenible. Por otro lado, la participación activa de los trabajadores en la definición, diseño, implementación y mejora continua de los
procesos puede aprovechar su conocimiento y experiencia para lograr mejoras significativas en los procesos. Además, la disponibilidad de recursos humanos, financieros y tecnológicos es fundamental para garantizar el éxito de la implementación de la gestión por procesos en la administración pública. En este sentido, es necesario que los gobiernos destinen los recursos necesarios para implementar la gestión por procesos y para fortalecer la cultura de mejora continua en la administración pública, a continuación se describen 6 factores a tomar en cuenta:
Liderazgo y compromiso de la alta dirección para impulsar y sostener la implementación de la gestión por procesos.
La gestión por procesos es un enfoque de gestión empresarial que se enfoca en mejorar continuamente los procesos de negocio con el objetivo de aumentar la eficiencia, la eficacia y la satisfacción del cliente. La implementación de la gestión por procesos en una organización puede ser un proceso complejo y desafiante que requiere la cooperación y el compromiso de la alta dirección, así como de otros miembros de la organización. Acá se argumenta que el liderazgo y compromiso de la alta dirección son factores críticos para el éxito de la gestión por procesos, utilizando dos referencias bibliográficas para respaldar esta afirmación.
En primer lugar, el liderazgo y compromiso de la alta dirección es un factor crítico en la implementación de la gestión por procesos, ya que puede influir en el nivel de apoyo y recursos que se destinan al proyecto. Según Ouellette y Joshi (2018), el compromiso de la alta dirección es un factor clave para la implementación exitosa de la gestión por procesos, ya que su apoyo financiero y estratégico es esencial para establecer un sistema de gestión por procesos sólido y sostenible. Además, la alta dirección puede establecer una cultura empresarial que fomente la mejora continua y la innovación en los procesos, lo que es esencial para mantener la relevancia y la competitividad de la organización.
En segundo lugar, el liderazgo y compromiso de la alta dirección también es importante para garantizar la adopción y el uso efectivo de la gestión por procesos por parte de los empleados de la organización. Según Harrington y Voehl (2018), la implementación de la gestión por procesos requiere un cambio cultural que afecta a toda la organización, y es necesario que la alta dirección comunique la importancia de este cambio y lidere con el ejemplo. Esto implica que la alta dirección debe asegurarse de que los empleados entiendan los objetivos de la gestión por procesos y los beneficios que pueden obtener de ella, y que proporcionen el apoyo y los recursos necesarios para garantizar que se implemente de manera efectiva.
Participación activa y empoderamiento de los trabajadores en la definición, diseño, implementación y mejora continua de los procesos.
La gestión por procesos es un enfoque empresarial que se enfoca en la mejora continua de los procesos de negocio con el objetivo de aumentar la eficiencia, la eficacia y la satisfacción del cliente. La participación activa y el empoderamiento de los trabajadores en la definición, diseño, implementación y mejora continua de los procesos son factores críticos para el éxito de la gestión por procesos. En este ensayo, se argumentará que la participación activa y el empoderamiento de los trabajadores son factores críticos para el éxito de la gestión por procesos.
En primer lugar, la participación activa de los trabajadores en la definición, diseño, implementación y mejora continua de los procesos es un factor crítico para el éxito de la gestión por procesos, ya que puede aumentar la eficacia y eficiencia de los procesos. Según Versteijnen, Schepers y Van de Wetering (2019), los trabajadores son los que tienen un conocimiento profundo de los procesos de negocio y pueden identificar problemas y oportunidades de mejora que pueden no ser visibles para la alta dirección. Al involucrar a los trabajadores en la definición, diseño, implementación y mejora continua de los procesos, se puede aprovechar su conocimiento y experiencia para lograr mejoras significativas en los procesos.
En segundo lugar, el empoderamiento de los trabajadores en la definición, diseño, implementación y mejora continua de los procesos es otro factor crítico para el éxito de la gestión por procesos. Según Van der Veen, Jansen y Van der Heijden (2018), el empoderamiento de los trabajadores es esencial para fomentar la innovación y la creatividad en la mejora de los procesos. Al empoderar a los trabajadores, se les da la responsabilidad y la libertad para tomar decisiones y proponer soluciones, lo que puede aumentar su compromiso y motivación hacia la mejora continua de los procesos.
Disponibilidad de recursos humanos, financieros y tecnológicos para la implementación de la gestión por procesos.
La gestión por procesos se ha convertido en una herramienta importante en la administración pública para mejorar la eficiencia y eficacia en la prestación de servicios públicos. Sin embargo, su éxito depende de varios factores críticos, entre ellos la disponibilidad de recursos humanos, financieros y tecnológicos. En este ensayo, se abordará este factor crítico para el éxito de la gestión por procesos en la administración pública.
Para implementar la gestión por procesos, es necesario contar con recursos humanos capacitados en el tema. Según Almeida, Carvalho, & Gomes (2020), el desarrollo de capacidades es un factor crítico para la implementación de la gestión por procesos en la administración pública. Esto implica que se debe invertir en la formación y capacitación de los empleados públicos en la gestión por procesos. Además, es importante que los empleados tengan una actitud positiva hacia el cambio y estén dispuestos a adoptar nuevos enfoques de trabajo. En este sentido, se destaca la importancia del liderazgo transformacional de la alta dirección para fomentar una cultura de mejora continua y participación activa de los empleados en el diseño e implementación de los procesos.
Comunicación efectiva y fluida en todos los niveles de la organización para la comprensión y adopción de la gestión por procesos.
La gestión por procesos se ha convertido en un enfoque cada vez más popular en la administración pública, ya que permite una mejor coordinación y eficiencia en la realización de tareas y servicios. Sin embargo, su implementación no siempre es fácil, y existen diversos factores críticos que deben ser considerados para asegurar el éxito del proceso. Uno de estos factores es la comunicación efectiva y fluida en todos los niveles de la organización.
Según Almeida, Carvalho y Gomes (2020), la comunicación efectiva es fundamental para asegurar que todos los miembros de la organización comprendan los objetivos de la gestión por procesos y su importancia para la mejora de la eficiencia y calidad del servicio público. Además, la comunicación es esencial para fomentar el compromiso y la colaboración de los trabajadores en la implementación de la gestión por procesos.
La importancia de la comunicación efectiva también es destacada por Navarrete, González y González (2018), quienes señalan que una comunicación clara y constante permite a los miembros de la organización comprender cómo sus tareas individuales se relacionan con los objetivos y procesos más amplios de la organización. Esto puede ayudar a aumentar la motivación y el compromiso de los trabajadores, lo que a su vez puede mejorar la calidad y eficiencia del servicio público.
Alineamiento de los procesos con los objetivos y estrategias institucionales.
En la administración pública, el éxito de la gestión por procesos depende de varios factores críticos. Uno de ellos es el alineamiento de los procesos con los objetivos y estrategias institucionales. Este factor es esencial para garantizar que los procesos apoyen la misión de la organización y contribuyan a la consecución de los objetivos estratégicos.
Según Hrebiniak y Joyce (2014), el alineamiento es un elemento clave para el éxito de la gestión por procesos en la administración pública. Los autores argumentan que «los procesos empresariales eficaces deben estar completamente alineados con la estrategia empresarial» (p. 35). Esto significa que los procesos deben estar diseñados y ejecutados de tal manera que contribuyan a la consecución de los objetivos estratégicos de la organización.
En este sentido, es importante que la administración pública defina claramente su misión, visión y objetivos estratégicos, y que los procesos se alineen con ellos. Esto requiere una gestión estratégica efectiva que incluya la identificación de los objetivos, la definición de las metas y la elaboración de planes y estrategias para alcanzarlos.
Diseño e implementación de mecanismos efectivos de seguimiento y evaluación de los procesos para medir el desempeño y la eficacia de la gestión por procesos.
La implementación de la gestión por procesos en la administración pública no solo implica la definición y documentación de los procesos, sino también el seguimiento y evaluación constante de su desempeño y eficacia. De esta manera, se pueden detectar oportunidades de mejora y garantizar la calidad de los servicios prestados. En este sentido, es esencial contar con mecanismos efectivos de seguimiento y evaluación de los procesos.
Según García-Alonso y Fuentes-Lombardo (2017), la implementación de un sistema de seguimiento y evaluación permite a las organizaciones públicas medir el desempeño de los procesos y evaluar la eficacia de la gestión por procesos. En este sentido, la implementación de indicadores de desempeño es una herramienta fundamental para el monitoreo y control de los procesos. Estos indicadores deben ser claros, medibles y alineados con los objetivos institucionales. De esta manera, se pueden identificar oportunidades de mejora y establecer planes de acción para su implementación.
Por otro lado, Juárez-Ramírez, Mora-Rivera y García-Alonso (2018) destacan la importancia de establecer un sistema de evaluación de la gestión por procesos que permita medir su efectividad. Para ello, proponen la implementación de un modelo de evaluación que contemple diferentes aspectos, como el cumplimiento de los objetivos institucionales, la eficiencia y eficacia de los procesos, la satisfacción de los usuarios y la capacidad de innovación de la organización. Este modelo de evaluación debe ser integrado en la cultura organizacional y formar parte de la estrategia institucional.
La implementación de un sistema de seguimiento y evaluación de los procesos no solo permite medir su desempeño y eficacia, sino también identificar oportunidades de mejora y establecer planes de acción para su implementación. En este sentido, es fundamental contar con un enfoque de mejora continua que permita a la organización pública adaptarse a los cambios del entorno y mejorar la calidad de los servicios prestados.
En este contexto, los sistemas de gestión de calidad, como la norma ISO 9001, pueden ser una herramienta útil para la implementación de un sistema de seguimiento y evaluación de los procesos. Según Juárez-Ramírez, Mora-Rivera y García-Alonso (2018), la implementación de un sistema de gestión de calidad permite a las organizaciones públicas establecer un marco de referencia para la gestión por procesos, así como establecer un sistema de seguimiento y evaluación de los mismos. Además, la norma ISO 9001 establece requisitos específicos para la medición del desempeño y la eficacia de los procesos.
3-. Discusión
Interpretación de los resultados
La implementación de la gestión por procesos en la administración pública requiere una serie de factores críticos para su éxito. Uno de los más importantes es el liderazgo y compromiso de la alta dirección, quienes deben liderar con el ejemplo y comunicar la importancia de la gestión por procesos a todos los empleados de la organización. Además, la participación activa y el empoderamiento de los trabajadores son factores clave, ya que al involucrar a los trabajadores en la mejora continua de los procesos se puede aprovechar su conocimiento y experiencia para lograr mejoras significativas.
Otro factor crítico para el éxito de la gestión por procesos es la disponibilidad de recursos humanos, financieros y tecnológicos. Es fundamental que los gobiernos destinen los recursos necesarios para implementar la gestión por procesos y para fortalecer la cultura de mejora continua en la administración pública. La formación y capacitación de los empleados públicos, la inversión en infraestructura tecnológica y sistemas de información, así como el fortalecimiento de los equipos internos encargados de la gestión por procesos son elementos fundamentales para garantizar el éxito de la implementación de la gestión por procesos en la administración pública.
La comunicación efectiva y fluida es otro factor crítico para el éxito de la gestión por procesos en la administración pública. Una comunicación efectiva permite una mayor comprensión y compromiso de los trabajadores, mejora la coordinación y colaboración entre los distintos departamentos y niveles de la organización, y facilita la identificación y optimización de los procesos que atraviesan toda la organización.
Finalmente, el diseño e implementación de mecanismos efectivos de seguimiento y evaluación de los procesos es un factor crítico para el éxito de la gestión por procesos en la administración pública. Estos mecanismos permiten medir el desempeño y la eficacia de los procesos, identificar oportunidades de mejora y establecer planes de acción para su implementación. Además, la implementación de un enfoque de mejora continua y la adopción de herramientas como los sistemas de gestión de calidad pueden mejorar aún más la efectividad de estos mecanismos.
III-. Conclusiones
Conclusión 1:
En este estudio de gestión de procesos, se aplicaron diversas metodologías para identificar los seis factores críticos que influyen en el éxito de la gestión por procesos. El modelo de Saaty fue utilizado para determinar los pesos de cada factor, mientras que el análisis de cluster permitió agrupar los factores en categorías. Los resultados revelaron que el compromiso y liderazgo de la alta dirección, el alineamiento de los procesos con los objetivos y estrategias institucionales, la participación activa y compromiso de los empleados, la disponibilidad de recursos, la comunicación efectiva y el monitoreo y medición de los procesos fueron los factores más relevantes.
La discusión de los resultados destaca la importancia del liderazgo comprometido y el compromiso de los empleados en la gestión por procesos. Estos factores tienen un impacto significativo en el éxito de la implementación y mejora continua de los procesos. Por lo tanto, las organizaciones deben enfocarse en desarrollar un liderazgo sólido y fomentar la participación activa de los empleados para maximizar los beneficios de la gestión por procesos.
Conclusión 2:
Otro hallazgo importante fue el alineamiento de los procesos con los objetivos y estrategias institucionales. Este factor asegura que las actividades operativas estén alineadas con los objetivos organizacionales, lo que mejora la eficiencia y los resultados. La discusión resalta la necesidad de comprender y adaptar los procesos para garantizar su coherencia con la dirección estratégica de la organización.
La discusión muestra que el alineamiento estratégico de los procesos es fundamental para lograr los objetivos organizacionales. Las organizaciones deben enfocarse en establecer una conexión clara entre los procesos y la estrategia, asegurando que cada actividad contribuya directamente al logro de los objetivos. Esto optimiza la eficiencia y evita la dispersión de esfuerzos, lo que conduce a mejores resultados.
Conclusión 3:
La disponibilidad de recursos, la comunicación efectiva y el monitoreo y medición de los procesos también fueron identificados como factores críticos en la gestión por procesos. Estos factores aseguran que se cuente con los recursos necesarios, se establezcan canales de comunicación claros y se realice un seguimiento adecuado de los procesos para identificar oportunidades de mejora.
La discusión de estos factores subraya la importancia de contar con los recursos adecuados, una comunicación efectiva y una monitorización constante de los procesos. Estos factores permiten un flujo de trabajo eficiente, una colaboración efectiva y una retroalimentación constante, lo que contribuye a la mejora continua de los procesos y a la obtención de resultados óptimos. Las organizaciones deben prestar atención a estos factores y dedicar recursos y esfuerzos para su correcta implementación.
IV-. Referencias Bibliográficas:
Aguilar, J. A. (2013). Administración pública. En J. A. Fernández, & M. A. Rodríguez (Eds.), Diccionario de administración y finanzas (pp. 25-26). Madrid, España: Editorial de la Universidad Complutense.
Almeida, M. A., Carvalho, J. A., & Gomes, J. A. (2020). Critical success factors for business process management implementation in the public sector: A literature review. Business Process Management Journal, 26(4), 809-832. doi: 10.1108/BPMJ-02-2019-0087
Bessant, J., & Francis, D. (1999). Developing strategic continuous improvement capability. International Journal of Operations & Production Management, 19(11), 1106-1119. https://doi.org/10.1108/01443579910291848
Córdoba, J. R. (2019). La gestión por procesos en la administración pública: un enfoque estratégico para la mejora de la gestión pública. Revista Científica de Administración, 7(13), 45-58. https://doi.org/10.5281/zenodo.3377109
Fernández, J. P., & López, J. C. (2010). Modelos de gestión por procesos. Editorial Club Universitario.
García, V. (2009). La reforma del Estado y de la Administración Pública en Guatemala: Antecedentes y perspectivas. En X. Albó & V. García (Eds.), Reforma del Estado y Administración Pública en América Latina (pp. 145-179). Buenos Aires: CLAD.
García-Alonso, L., & Fuentes-Lombardo, G. (2017). La gestión por procesos en la administración pública: una revisión de la literatura. Investigación administrativa, 46(118), 7-17. https://doi.org/10.1016/j.inadm.2016.07.001
García-Sánchez, E., García-Morales, V. J., & Martín-Rojas, R. (2019). Assessing the impact of lean management on quality management systems and financial performance. Journal of Cleaner Production, 219, 951-959. https://doi.org/10.1016/j.jclepro.2019.02.135
González, J. M., & de la Fuente, E. A. (2016). Gestión por procesos en la administración pública: factores críticos de éxito. Revista de Administración Pública, 198, 119-145.
Juárez-Ramírez, R., Mora-Rivera, J. L., & García-Alonso, L. (2018). Alineamiento estratégico de procesos: revisión de la literatura. Ciencias Administrativas, 4(2), 9-26. https://doi.org/10.22206/cadm.23170406.2018.2.1552
Kerzner, H. (2017). Project management metrics, KPIs, and dashboards: A guide to measuring and monitoring project performance. John Wiley & Sons.
López, M., Larios, G., & González, M. (2018). La gestión por procesos en la administración pública: una revisión bibliográfica. Revista Internacional de Administración Pública, 18(2), 39-61. https://doi.org/10.17423/1726-5274-2018-18-2-39-61
Solares Mancilla, M. G. (2023). Definición de un proceso en la gestión por procesos en la Administración Pública. Recuperado de [http://www.inap.gob.gt].
Navarrete, C., González, A., & González, C. (2018). A review of critical success factors for business process management in the public sector. Revista de la Facultad de Ingeniería, 33(2), 103-111. doi: 10.19053/01211129.v33.n2.2018.7232
Ouellette, P., & Joshi, M. (2018). The implementation of process management: Critical success factors. International Journal of Quality & Reliability Management, 35(5), 1065-1078. doi: 10.1108/IJQRM-03-2017-0064
Pérez, A., Cortés, P., & Vargas, J. (2019). Diseño de un sistema de gestión de procesos en la administración pública. Ingeniare. Revista chilena de ingeniería, 27(2), 283-295. doi: 10.4067/S0718-33052019000200283
Rodríguez, J. (2014). Implementación de la gestión por procesos en el sector público de Guatemala: Una revisión de la literatura. Revista Científica de Administración Pública y Política Pública, 3(2), 47-60.
Van der Veen, J., Jansen, J., & Van der Heijden, B. I. (2018). The empowering leadership questionnaire: The construction and validation of a new scale for measuring leader behaviors that empower followers. Journal of Business and Psychology, 33(3), 313-335. doi: 10.1007/s10869-017-9528-1
Versteijnen, M., Schepers, J., & Van de Wetering, R. (2019). Employee involvement in business process improvement: A process perspective. Total Quality Management & Business Excellence, 30(3-4), 287-303. doi: 10.1080/14783363.2016.1258716
Villoria, M. (2012). Innovación en la gestión pública. Madrid, España: Centro de Estudios Políticos y Constitucionales.
Es claro que cualquier decisión a la que nos enfrentemos día a día, no es simplemente una variación dicotómica entre si o no y que en alguna medida requiere un poco de análisis para determinar la opción más favorable. En España las predicciones en las últimas elecciones fallaron, en México igual y el último gran fiasco fue en el Reino Unido, en donde no solo fallaron las encuestas pre-elecotorales sino también falló una encuesta de salida de YouGob.
Repasando los resultados en España, hoy sabemos que sólo TMG empresa que había sido contratada por el Partido Popular no se había sorprendido ante los 137 escaños que habían obtenido, ellos habían estimado 135, el PSOE celebraba que no hubiera el sorpasso y la restante parte de izquierda se lamentaba que no hubieran resultado como habían anunciado las encuestas, los principales medios de prensa, tanto de televisión, radio y escrita no daban cuenta de sus predicciones, todos se habían equivocado.
En México no fue muy diferente que digamos, aunque no eran elecciones presidenciales, se jugaban doce gobernaciones y el derecho de conformar el grupo de constitucionalistas en el nuevo estado mexicano del extinto Distrito Federal, allí las cosas avecinaban que el PRI permanecería en la mayoría de los estados, incluso luego de terminar la jornada electoral el presidente del partido se atrevió a proclamarse como vencedor, cuando la mayoría de casas encuestadoras no sabían con seguridad que estaba pasando, el único medio que daba ganadores fue Milenio, el director de la casa que suministró datos a esta casa de prensa, en una entrevista pos electoral no aceptó que se había equivocado y con argumentos poco creíbles concedió que sus resultados tenían credibilidad en el momento de su publicación. Sus colegas del medio mexicano, hicieron autocrítica y aceptaron que se habían equivocado e inclusive absorbieron parte de la culpa del duro golpe de Milenio sobre el gremio.
En el Reino Unido las encuestas se hicieron por medio de llamadas telefónicas (están prohibidas las encuestas a boca de urna), en México algunos puntos de muestreo no eran accesibles dado el nivel de violencia, eran las principales causas. Y razones hay muchísimas, desde los errores de realizar una estimación pequeña de la muestra, o una selección mala o un bajo nivel de respuesta, en EEUU por ejemplo durante la última década se tiene que hablar con 20 personas para obtener un solo dato confiable y ése camino está tomando el resto del mundo, incluidos en Guatemala.
Pero existe un caso extraordinario que ocurrió hace un par de semanas, las elecciones presidenciales de Perú, allá existen tres casas encuestadoras de renombre las cuales luego de prácticamente realizar encuestas durante todo el proceso, las tres tenían datos contundentes sobre un empate técnico. Las tres casas hicieron el ejercicio de realizar encuestas a boca de urna y dos de ellas también hicieron conteos rápidos, dos de las casas daban como ganador al que finalmente salió victorioso tanto en simulacros, en encuestas a boca de urna y en los conteos rápidos, pero junto a los medios la decisión fue abordar la noticia como un empate técnico, dado que el error era por mucho mayor a el distanciamiento porcentual que separaban a los candidatos. Y en efecto la mesura se contagió hasta el punto de que los mismos candidatos fueron responsables y mesurados. Y cabe resaltar que la población fue extremadamente cauta.
Pero la pregunta al inicio fue ¿Para qué sirven las encuestas?, bueno mucho se puede especular al respecto de que si fallan o no, si son buenas para predecir o no. Y bueno en primer lugar no sirven para predecir, sino sólo son una forma de entender lo que pasó. Y en ése sentido corregir campañas o formas de percepción de los segmentos de la población. Y en efecto como nos hemos dado cuenta al momento de dar una valoración sobre las encuestas, cuentan las formas y aspectos técnicos del muestreo, pero son más relevantes la interacción que existe entre el medio que publica y la mesura de los medios para hacer una nota periodística y conviene tener políticos a la altura que actúen de acuerdo a las circunstancias con mucha responsabilidad.
Pero sobre todo depende de las masas de la población del objeto de estudio que consumen las noticias y que apoyan candidatos, dado que nosotros estamos determinados por nuestras sentimientos y conviene saber utilizar la información a nuestro favor, no como algo que va suceder, sino como una explicación a lo que fue.
En mi opinión existen dos cosas fundamentales que deberían preguntarse sobre una encuesta, primero la ficha técnica de la misma que debería contener el porcentaje de no respuesta y segundo aunque también debería estar en la primera, quien está financiando dicha encuesta, si ése fuera el punto el PAN de Juan Gutiérrez nos debería muchas respuestas en las pasadas elecciones.
Y por eso también hay que decir que las próximas elecciones en las que usted participe como votante o simplemente como espectador, también estará un poco más preparado para saber en qué o quién confiar. Parafraseando a una amiga, decir que “las encuestas son como un bikini, muestran mucho pero ocultan lo esencial” y en efecto no olvide que las encuestas no sirven para que usted tome una decisión, sino su decisión o inclinación debe reflejarse en ella, porque aunque usted crea que no se parece a alguien más, si se parece.
En mis cálculos para determinar el resultado de la final de la Liga de Campeones de la UEFA, basado en ocho variables, el Real Madrid Club de Fútbol tiene una probabilidad de ganar del 35.6%, de empatar un 26.4 y que el Club Atlético de Madrid gane es de 37.9%. Si lo que ustedes quieren saber es quien alza la orejona, las probabilidades favorecen al club colchonero con un 51.6%.
Donde;
P(x)= es la probabilidad de que gane el Real Madrid
a= las probabilidades de un evento al azar
b= encuentro y rival de las semifinales del torneo.
c= récord de los equipos a lo largo del torneo + goles.
d= récord de los últimos 10 encuentros disputados por equipo + goles.
e= comparación de calidad del equipo, cuerpo técnico y plantilla.
f= probabilidad de tres casas de apuestas.
g= récord de los últimos 10 encuentros entre ellos
h= récord histórico entre ellos
De acuerdo a estas variables elaboré el siguiente cuadro auxiliar que desglosada cada una.
a
(0.3)
b
(0.055)
c
(0.055)
d
(0.055)
e
(0.055)
f
(0.20)
g
(0.17)
h
(0.11)
Real Madrid
33.3
33.3
61
56
47
36.2
10
53
Empate
33.3
n/a
n/a
n/a
n/a
36.1
40
22
Atlético de Madrid
33.3
66.7
39
44
53
27.7
50
25
En cuanto a mi, si tuviera que apostar, apostaría que gana 2-0 el Real Madrid C.F. con goles de Ronaldo y Bale. Aunque deben de comprender que yo le voy al Madrid y no puedo apostar en contra.